llmdoc: 解决AI Coding的最后100米
Table of Contents
llmdoc: 解决AI Coding的最后100米
在过去一年半的时间里, 我的工作流有了巨大的变化, 也亲眼见证了 AI Coding从兴起到现在的全面铺开, 个人工作模式已经被彻底颠覆了
当我们回顾 2025 年的变化, 从年初的 gemini 2.5 到 sonnet 4.5, gpt-5-codex, opus 4.5, gemini 3, gpt-5.2-codex.
我们应该认为: 模型的能力进步速度没有变得缓慢, 而且Cursor / Claude Code / OpenCode这类Coding Agent 的兴起, ToD 的应用也以令人难以预料的速度推进.
随之而来的有另一个问题: Context, 是的上下文构建, 而且我想要说的是在严肃的面向生产的环境中的 Context, 这不是 chatbot 中用personality 这种可以糊弄过去的, 代码更新留下了遗漏是真的会出现线上故障的.
让我们再看一下现在的这些Coding Agent 提供的能力吧:
- AGENTS.md / CLAUDE.md: 注入到 User Message 满足 Context定制化的需求
- SubAgent / Fork-Context: 通过增加并行度实现 Task 的更快解决
- Skill / Command / Workflow: 虽然都在鼓吹 Skill 的渐进式披露, 但是我认为对于编程这种极度明确的场景太多的 Skill只会让你的模型编程笨蛋
但是, 还差了一些东西, Agent 实际上并不了解你的仓库, 我这里的了解指的是 Agent 实际上是通过Claude.md + 大量阅读代码文件才感知到了当前的环境.
这是正常的工作模式, 我们也习惯于这一点, 但是这不是一个好的路径, 如果使用 codex-cli 的人对此应该深有感触: 不断的不断的阅读代码文件, 甚至是完全不需要阅读的代码文件, 在 Context 足够解决问题的时候, 才开始解决问题.
Context Floor
我个人会把 “满足 Agent 解决需求的 context 的丰富度” 称之为: Context Floor
- 调用了多少工具
- 占用了多少 Token
- 关键信息的密度
现在让我们回过头来看, 一些经典的解决方案:
- LSP MCP: 通过提升关键Symbol密度 + 大量的工具调用 实现快速到达context floor
- ACE / RAG: 通过少量的工具调用 + 稀疏的关键信息密度, 很难保证信息的关联性和有效性
- Agentic RAG: 让 Agent 做一次信息的搜集, 提供一份概要, 一般使用 SubAgent, 在 claude code 中的
explorer就是承担了类似的作用, 虽然 subagent 执行任务可以保证 master agent 上下文足够干净, token 占用量也不高, 关键信息密度也很高, 但是耗时太久了 TTCR (Time to Context Floor)实在是难以忍受
那么, 有没有一个解决方案足够快, 信息密度足够高, 主Agent的Token 占用足够少, 信息和任务存在强关联而且有效呢?
我的解决方案
https://github.com/TokenRollAI/cc-plugin
调试了一个月, 在公司内验证了3 个月之后,我觉得在现在时间节点的 SOTA 模型的加持下, 这套方案足够满足需求了
llmdoc + subagnet RAG
过去我有几个帖子说名字他的诞生的思考过程, 这里就不在详细的介绍
llmdoc
一个在设计之处就用来解决AI 快速获取高密度信息 + 人类可读性的文档系统
脱胎于 diataxis, 做了些微不足道的改动
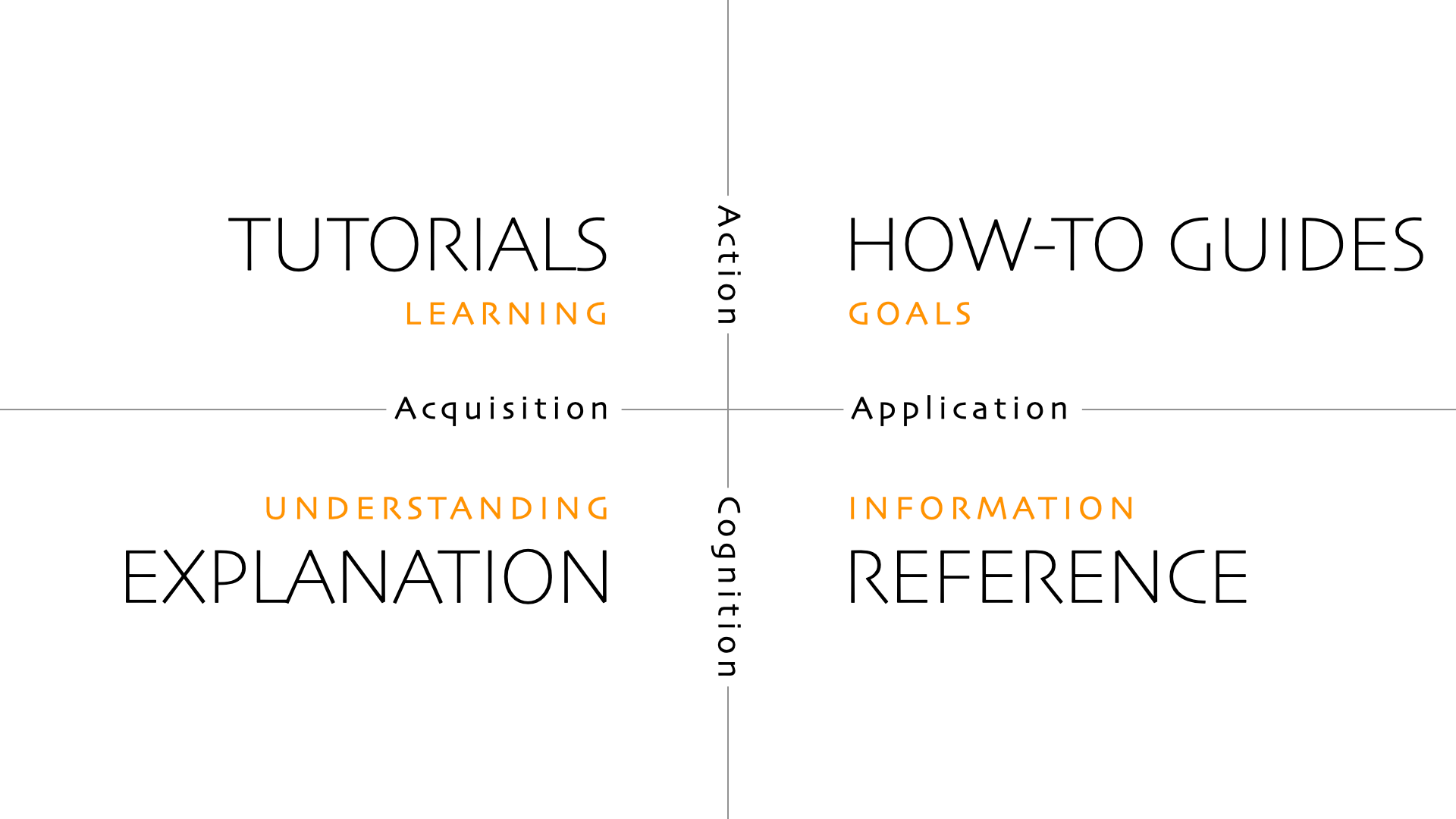
- 利用 Agent 能够快速批量 Read的能力, 文档中保留最关键的文件路径+负责的模块说明
- 项目概览 + 架构 + 通过主题串联的 guides + refrence
以上作为基础, 在代码库中插入一个 llmdoc, 满足人类可读性 + Agent 可读性
示例: https://github.com/TokenRollAI/minicc/tree/main/llmdoc
subagent RAG
为了解决并行度的问题, 必须要引入 subagent, 但是 subagent 用来做什么呢?
主要是两件事情:
- 调研: 基于 llmdoc + 现有的代码文件, 调研拆解后的任务作为前置条件
- 记录: 在完成了编码任务之后, 自动的更新维护 llmdoc
问题
效果当然非常好, 或者说, 自从有了这一套解决方案之后我没有再使用过其他乱七八糟的 plugin
但是有一个问题: 贵
而且不是有点贵, 大概是用1.5倍的价钱完成了从 85 分 -> 90 分的效果, 在一些简单的项目中, 效果一般, 但是越复杂的项目收益越好.
效果
在我们公司的线上业务中, 后端代码仓库大概有 10W 行代码, 这套系统工作出色, 在几乎所有的情况下, 都能够准确的完成需求.
在建立了 llmdoc 的基础上, 根据需求的大小, 需求完成的成本大概在 1 - 5 刀, 而且最关键的是: 人类介入的次数大大降低, 只需要 Review 代码, 以及执行少量的修改后, 就能够放心交付.
现在也在我们的前端团队内开始推进, 效果依然出色.
我推荐大家使用 cc-plugin, 强烈推荐!